Motivation
- Software is not data [1]
- Definition of Research Software [2]:
- All code and software artifacts that are used, produced, or might be related to the research process in one or more stages of the research lifecycle and regardless of the layer of the software stack.
- Stack of Research Software [3]
- contextual information needs to be permanently coupled to the dataset [4]
- recommendation to use docker for interoperability [5]
Missing Aspects:
- linkage between data, software and its context manually and not
by design
- The FAIR Principles were not developed for the combined entity of software and data.
Research Data Management Container (RDMC)
The RDMC is the heart of the efforts made by NFDIxCS. The RDMC is a portable object that manages itself in terms of access, specific workflow and all the data, software and further information to describe the data and all the means to access / bring the data back to life. These RDMCs will be hosted by a few service providers initially within the consortium and by trusted service providers.
Concepts
The design of the RDMC is guided by several principal concepts, which will be outlined in this section. Actual consequences for the RDMC architecture will be derived from these concepts in the subsequent sections.
Connecting Data, Software, and Context through a Container
Research is not a series of isolated steps. Therefore, it’s essential to permanently link contextual information with datasets [4]. The container facilitates this linkage by consolidating diverse artifacts of varying formats and referencing any additional required artifacts in one location. To illustrate the types of data, software, and context being referred to, several examples are provided in the NFDIxCS proposal:
| Discipline | Examples | Data | Software | Context |
|---|---|---|---|---|
| Theoretical Computer Science | Formal proof for interactive theorem proof | data for testing, evaluation and training; for example libraries of proof problems | theorem prover | |
| Software Engineering and Programming Languages | ||||
| Security and Dependability | ||||
| Operating, Communication, Database and Distributed Systems | ||||
| Visual Computing | ||||
| Business Information Systems | ||||
| Computer Architecture and Embedded Systems | ||||
| Massively Parallel & Data Intensive Systems | ||||
| Artificial Intelligence and Machine Learning | ||||
| Interactive Systems |
Several open questions emerge when considering the balance between the stability and flexibility of the container, especially in its role connecting data, software, and context. On one hand, the container represents a snapshot of current research, ensuring consistency. On the other, there’s a need for adaptability as datasets change or grow and software evolves. Stemming from this dynamic:
- Versioning of Containers (x.y.z): When software undergoes updates, each iteration can be labeled using Semantic Versioning. For data, there isn’t a widely adopted versioning scheme. So, how should updates in data, data schema, or software be addressed? Is there a method similar to semantic versioning where the version number provides insights into the nature of updates from one container to the next?
- Container Structure: How should the container be structured so that the presented research can be replicated with a different dataset? Or perhaps the data might be utilized by alternative software. Are there strategies to interchange parts of the container?
- Archiving External API Data: How can data from an external API, used outside the container, be archived? This is especially pertinent when the responses from an API call are integral to subsequent work.
The container itself receives a stable ID, so that other containers, and scientific work, can reference this research artefact and thus create a network of rich artifacts where all contextual elements are available for any of its individual pieces.
As Open as possible
As already mentioned above, research can produce and use entirely different artifacts. Consequently, the container must be as open as possible to allow for any type of artifact in any data format and for any type of reference to any other place. Driving this idea further, there will even be no single implementation of code managing RDMCs, but the opportunity to create multiple implementations that all read or create RDMCs conforming to the standards defined by NFDIxCS.
Embracing multiple standards
While there is a need to establish a standard for RDMCs, it doesn’t imply neglecting existing standards. Embracing openness requires us to accommodate various standards across different areas of research data and software management. These areas, where multiple standards need to be addressed or prevalent standards should be adopted, are identified by the NFDIxCS Community and encompass the following topics:
- Metadata Taxonomy and Semantic Aspects
- Metadata Formats:
- Container technology
- Execution Environments
- Legal and ethical Aspects
- Security and Privacy
- Persistent Identifier
- Publication Process
- Citation and Attribution
The container also needs the flexibility to adapt to new standards if there are changes in the underlying technology or schemas.
Using archives vs creating an archive
The RDMC and its platform should not be built as another archive. Constructing an archive requires significantly more resources, and the landscape for archiving in individual disciplines would be expanded by a new archiving system. As a result, NFDIxCS doesn’t plan to create a new archive but to utilize existing solutions. The RDMC and its platform must architecturally act as mediators. They should provide users the opportunity to point to existing data and software archives and orchestrate them into a unified container. Defining this mediation space raises various questions:
- How to address researchers who haven’t used any archive? The platform must accept the data and software, request the researcher’s permission to archive, and use prevalent data or software archives to store the artifacts.
- Consequently, is the RDMC merely an empty container, with data
and software always used to create an executable container? Several
aspects need consideration:
- For short-term usage, such as when the container is associated with a publication, the container can be constructed and stored for consistent access whenever a reviewer, conference participant, or journal article reader wants to reproduce the results. There needs to be mechanisms in place for long-term archiving after a set time limit or upon the introduction of a new iteration of the container.
- For long-term usage, the container doesn’t need to be instantly available. Archives are excellent for preserving data or software over extended periods. If constructing a container is necessary, users should be informed that it might take some time.
- What happens if a utilized archive goes offline? To avoid complete dependence on external archive operators, there’s, for instance, a mirror of the Software Heritage at UDE. However, archives are designed for long-term knowledge preservation. If an archive goes offline, several stakeholders would be at a loss. Incorporating archives into infrastructure might also justify their continued operation. The forthcoming platform must verify the availability of every used archive and have mechanisms to address lost data/software in archives.
- How can we ensure the container’s executability? The execution environment will be stored in NFDIxCS storage systems. If an RDMC is constructed with a specific execution environment, that environment must be preserved and archived within our systems.
Guarantees / Levels of consistency and conservation
The concept sketched so far is delibarately open to multiple implementations, sets little constaints and gives great freedom in using the opportunities provided. Consequently, not all RDMCs will be in exactly the same shape and it is important to know what can be achieved by using one option or another. We first examine the different options and their consequences. Subsequently, we provide a sequence of level, where each level provides more guarantees regarding the consistency of the container and the conservation of data than the previous level. These levels may be promoted by badges declaring the conformance to one of the levels in the platform later on.
- Linking resources vs. placing resources within the RDMC -> Only the latter can guarantee that resource is available whenever RDMC is available + something about anonymous access for reviews?
- Creating RDMC manually vs. creating it via platform or other piece of software -> Only the latter can include automated checks for consistency
- Using passive vs. active RDMC -> ???
- Storing encrypted vs. non-encrypted resources -> ???
- Declaring a minimal set of predefined metadata vs. using arbitrary metadata -> ???
Levels:
- Lowest level: Links to external resources, RDMC built manually, no encryption, arbitrary metadata
- …
- Highest level: Every resource included in the RDMC, built by software/platform as active RDMC, using encryption, providing defined metadata
Manifest File
The RDMC comes in different “flavours”, probably implemented in ascending order from simple to complex during the development process of NFDIxCS. The minimal contant of a container is a manifest file explaining the RDMC contents in machine-readable format, also containing signature and versioning information. Any resources associated with the RDMC may be provided as references to external data sources. This way, it is easy to set up a minimal RDMC if data is already published in an appropriate repository and if no additional guarantees are relevant.
Active vs. passive containers
Besides the manifest file, a RDMC may contain a file structure that has three key components:
- A folder (that may have many sub-folders) for the actual research data. Sub-folders or individual files within these folders may be encrypted.
- A folder that contains meta data. Following the concepts of being as open as possible and embracing multiple standards, the RDMC makes no restrictions about the meta data formats used, and it can contain multiple meta data files for the same research data.
- A folder containing access information to encrypted data. For multiple reasons, research data cannot be encrypted directly with a private key of the target audience. Instead, research data is encrypted and the keys for decryption are stored in multiple key rings within the RDMC. Each key ring can be made available to individuals or groups based on their private key. Details mus be specified by a security expert.
The simplest way of creating a RDMC is to assemble its contents manually in the way sketched above, describe them properly in a manifest file and package the resulting file structure into an archive file. This is not the preferred way of handling RDMCs, as this provides little guarantees with respect to the consistency of its contents.
The platform will provide a service by which a RDMC can be build and managed via a UI. (Potantially a standalone software tool will be available to do the same.) Rights may restrict write access. The platform will implement mechanisms to ensure the integrity of the RDMC based on signatures. Nevertheless, the result will still be a “passive” container that can only be managed manually or via the platform.
In order to create an active RDMC, the file structure can be established within an executable container (like Docker). A piece of software will be developed by NFDIxCS that can be added to the container as an entry point. When started, it will provide a UI similar to the platform that grants access to the RDMC contents. Rights may restrict write access. The piece of software will implement mechanisms to ensure the integrity of the RDMC based on signatures.
The piece of software may provide additional services that resolve dependencies to reusable execution environments and thus can setup an environment automatically.
Implementing the RDMC
NFDIxCS will provide a specification for the RDMC contents and the piece of software. NFDIxCS will provide a reference implementation based on one container technology and one programming language for the piece of software. Other implementations are welcome.
The Platform
Architecture
The model of the architecture will be oriented on C4. C4 leads the architects to create visualizations for different detail levels:
- Context: Describes at the system level which individuals, actors, or external systems interact with the system being developed.
- Container: Describes at the application system level how they interact with each other and which containers act with external actors or systems.
- Component: Corresponds to the meaning from software development and visualizes the individual software components and their interaction.
- Code: Is a description similar to a UML class diagram. It is recommended not to model this level but to generate it directly from the development environment.
Context
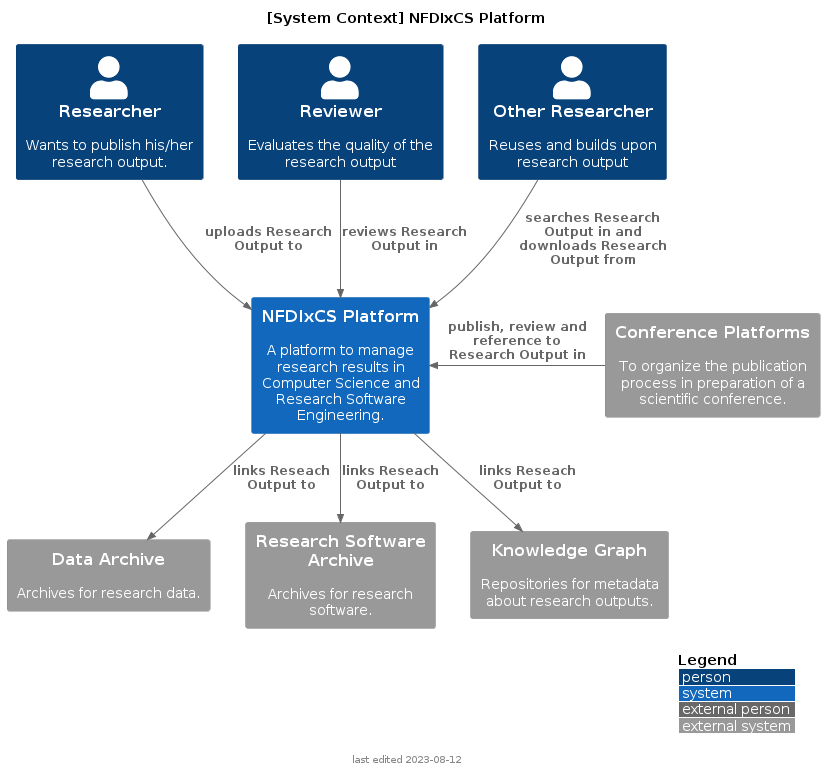
Users actively using the NFDIxCS Platform:
- Researchers at any stage of their experience level wants to publish their research artefacts, connect their artefacts for a publication
- Reviewers ensure the quality of the artifacts. Another option could be for them to review a paper publication in which an artifact from this platform is linked. In such cases, the reviewers could use the artifact to reproduce the results of the paper publication. In both scenarios, the reviewers need access to the artifact and should be able to execute it.
- Researchers (referred to in the figure as other Researchers) want to search for algorithms to integrate them into their research, replicate research results, answer different research questions using the same artifact, or utilize the artifact in a more application-oriented scenario.
Container
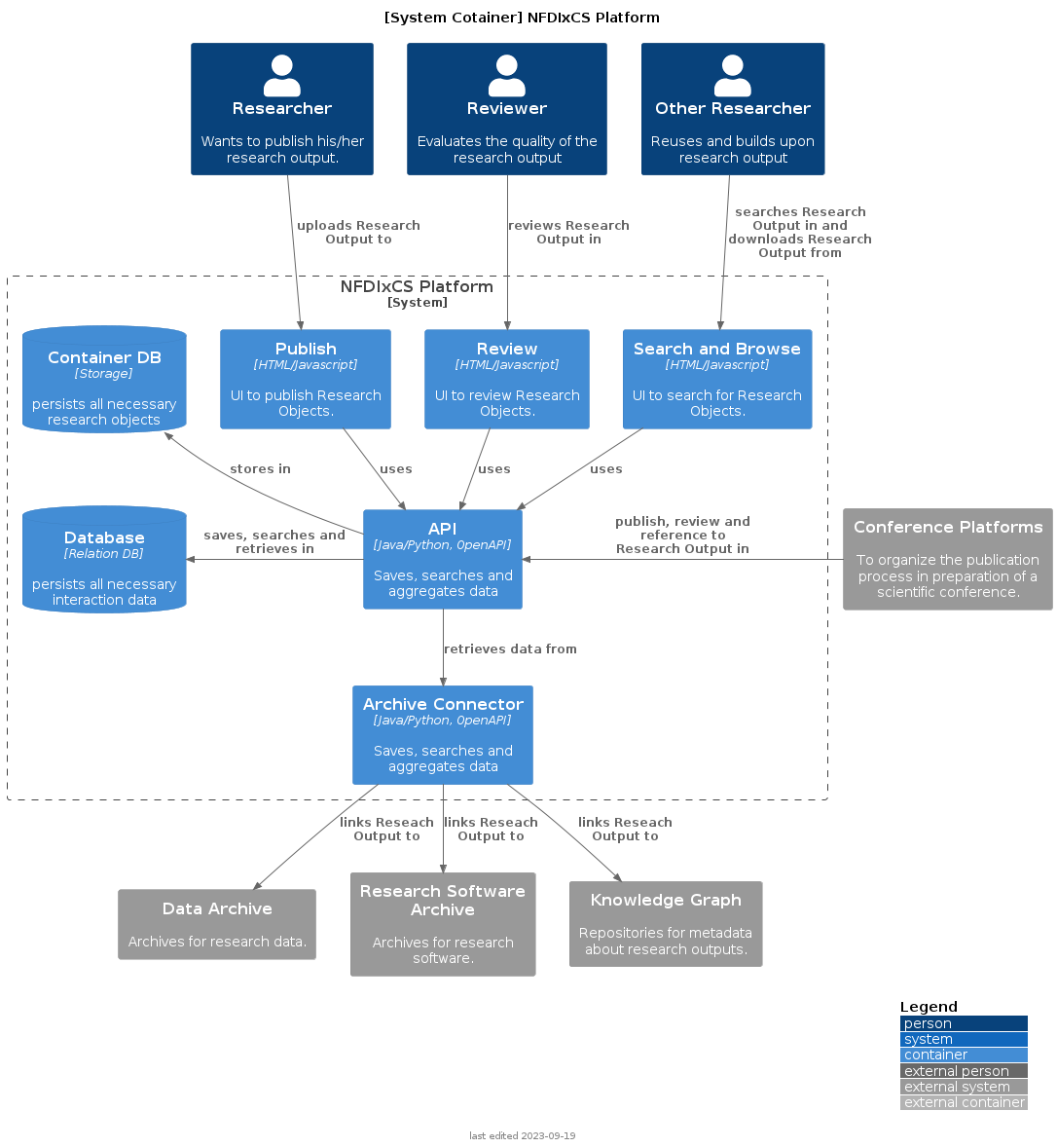
Glossar
| Abbreviation | Full Form |
|---|---|
| RDMC | Research Data Management Container |